
分布式系统中的读写模型
分布式系统是由多个节点(指代一台服务器、存储设备等)构成,由于网络异常、宕机等节点并不能保证正常工作,特别是在节点数量很大的时候,出现异常状况的节点几乎是肯定的。为了保证系统的正常运行,能够提供可靠的服务,分布式系统中对于数据的存储采用多份数据副本(注:这里的副本并非只用来备份,它可参与提供系统服务)来保证可靠性,也就是其中一个节点上读取数据失败了那么可以转向另外一个存有相同数据副本的节点读取返回给用户。这个过程对于用户来说是透明的。那么随之而来的就会带来数据的副本数据的不一致性,例如:用户提交一次修改后,那么原先保存的副本显然就与当前数据不一致了。解决这个问题最简单的方法 Read Only Write All ,就是在用户提交修改操作后,系统确保存储的数据所有的副本全部完成更新后,再告诉用户操作成功;而读取数据的时候只需要查询其中的一个副本数据返回给用户就行了。 在很少对存储的数据进行修改的情形下(例如存档历史数据供以后分析),这种解决方案很好。如遇到经常需要修改的情形,写操作时延时现象就很明显,加上并发或者连续的执行的话效率就可想而知了。实质,这是由于 Write 和 Read 负载不均衡所致,Read 很轻松,Write 深表压力!
解释:
简单概括说来就是, Quorum 是一种集合 , l 中任意取集合S,R ,S,R 都存在交集。当然,本文并不打算多讲它的数学定义方面的理解,这里只是提供个信息,看不懂也没事联系到前面的分布式读写模型就能很容易理解这个了。
回到文章的开头,我们来看看是怎么运用Quorum机制来解决读写模型中读写的负载均衡。其实,关键的是更新多少个数据副本后,使得读取时总能读到有效数据?
读模型:
假设总共有 N(副本个数) 个数据副本,其中 k 个已经更新,N-k 个未更新的,那么我们任意读取 N-k+1(读取副本的个数)个数据的时候就必定至少有1个是属于更新了的k个里面的,也就是 Quorum 的交集,我们只需比较 读取的 N-k+1 中版本最高的那个数据返回给用户就可以得到最新更新的数据了。
写模型:
我也只需要完成k(写更新副本的个数,大于N/2)个副本的更新后,就可以告诉用户操作完成而不需要 Write All 了,当然告诉完用户完成操作后,系统内部还是会慢慢的把剩余的副本更新,这对于用户是透明的。可以看到,我们把 Write 身上的部分负载转移到了Read上,Read读取多个副本,使得Write不会过于劳累,不好的是弱化了分布式系统中的数据一致性。至于转移多少负载比较合适,这个需要根据分布式系统的具体需求中对数据一致性的要求。不过,CAP 理论告诉我们没有完美的方案。
基于Quorum投票的冗余控制算法
Quorom 机制,是一种分布式系统中常用的,用来保证数据冗余和最终一致性的投票算法,其主要数学思想来源于鸽巢原理。
在有冗余数据的分布式存储系统当中,冗余数据对象会在不同的机器之间存放多份拷贝。但是同一时刻一个数据对象的多份拷贝只能用于读或者用于写。
该算法可以保证同一份数据对象的多份拷贝不会被超过两个访问对象读写。
算法来源于[Gifford, 1979][3][1]。 分布式系统中的每一份数据拷贝对象都被赋予一票。每一个操作必须要获得最小的读票数(Vr)或者最小的写票数(Vw)才能读或者写。如果一个系统有V票(意味着一个数据对象有V份冗余拷贝),那么这最小读写票必须满足:
-
Vr + Vw > V
-
Vw > V/2
第一条规则保证了一个数据不会被同时读写。当一个写操作请求过来的时候,它必须要获得Vw个冗余拷贝的许可。而剩下的数量是V-Vw 不够Vr,因此不能再有读请求过来了。同理,当读请求已经获得了Vr个冗余拷贝的许可时,写请求就无法获得许可了。
第二条规则保证了数据的串行化修改。一份数据的冗余拷贝不可能同时被两个写请求修改。
算法好处
在分布式系统中,冗余数据是保证可靠性的手段,因此冗余数据的一致性维护就非常重要。一般而言,一个写操作必须要对所有的冗余数据都更新完成了,才能称为成功结束。比如一份数据在5台设备上有冗余,因为不知道读数据会落在哪一台设备上,那么一次写操作,必须5台设备都更新完成,写操作才能返回。
对于写操作比较频繁的系统,这个操作的瓶颈非常大。Quorum算法可以让写操作只要写完3台就返回。剩下的由系统内部缓慢同步完成。而读操作,则需要也至少读3台,才能保证至少可以读到一个最新的数据。
Quorum的读写最小票数可以用来做为系统在读、写性能方面的一个可调节参数。写票数Vw越大,则读票数Vr越小,这时候系统写的开销就大。反之则写的开销就小
该算法满足CAP理论的 A(可用性)和P(容错性),不满足 C(一致性)
NWR 策略读写模型的例子
假设两个进程同时来更新这份数据,进程W1要把值改写成C,进程W2要把值改写成B,那就有可能出现下图的情形,两个进程各拿到一个副本改写,都认为自己的写操作是成功的,结果却留给系统三个不同的副本,这样就出现数据副本不一致的问题。
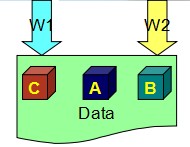
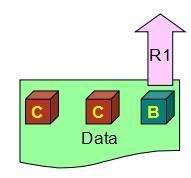
所以公式W> N/2, 实际上变成了一个写的锁,意味着只有写了过半数副本的才算写成功,拿不到的就返回失败,解决了竞争的问题。如下图,W1的会话成功,W2的会话就返回失败。

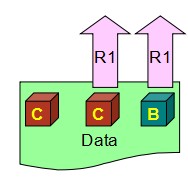
W> N/2,同时意味着不需要把所有的副本都写完,未完成的留给系统自己后台慢慢同步,那这个时候问题就来了,一个新的会话过来读数据的时候,分配到的副本有可能是没来得及更新的。这时候R1读回去的就是过时的数据B,而非最新的数据C
第2个公式变形下就是R> N-W,R=2就避免正好倒霉读到没更新的那一个。这样读回去C和B两个数据,再比较后取最新的C。所以W+R> N 能够保证每个读的请求至少读到一份最新的数据,
https://my.oschina.net/manmao/blog/618344



相关推荐
#资源达人分享计划#
quorum, 支持数据隐私的Ethereum的permissioned实现 仲裁 仲裁是基于ethereum的分布式分布式分类帐协议,具有事务/协定保密性和新的一致性机制。仲裁是 go fork,并与 go-ethereum发布 releases 。go-ethereum的关键...
quorum联盟链运行流程图
server程序入口(启动类在zookeeper-server/src/main/java文件夹中,org.apache.zookeeper.server.quorum.QuorumPeerMain),program argument为conf/zoo.cfg,将conf/log4j.properties配置拷贝到zookeeper-server/...
云原生: CnosDB 有原生的分布式设计、数据分片和分区、存算分离、Quorum 机制、Kubernetes 部署和完整的可观测性,具有最终一致性,能够部署在公有云、私有云和混合云上。提供多租户的功能,有基于角色的权限控制。...
提出一种基于发布/订阅模式的分布式SCADA消息中间件的设计方案,该方案使用了N-Tree结构将系统消息进行逻辑区域划分,设计了一套完善的消息传递与反馈处理机制,方案中利用Quorum-Based改进型算法确保了分布式节点的...
2.2 Quorum读写 2.3 不不⼀一致产⽣生原因 2.4 Hinted handoff 2.5 Read repair 2.6 Manual repair 3.Cassandra应⽤用场景 4.总结 视频是mp4格式,配套文档下载地址如下: 链接: ...
quorum_blog 通过仲裁保持一致性的分布式博客
quorum.js:Quorum 的 JavaScript API quorum.js是延期增加了对API的特定支持。 :warning: 项目弃用通知 :warning: quorum.js 库将于 2021 年 12 月 31 日弃用,从我们停止支持该项目之日起。 quorum.js 库已弃...
NULL 博文链接:https://kabike.iteye.com/blog/2224252
华为存储双活仲裁软件
为此,我们需要一个分布式锁定机制,用于最多32台服务器,每台服务器都将运行minio server 。 锁定机制本身应该是读取器/写入器互斥锁,这意味着它可以由单个写入器或任意数量的读取器持有。 对于 ,分布式版本的...
为解决现有的quorum系统...该系统借助代理动态调整各quorum,并按数据存储时段将各节点划分为不同的等级,此外还设计了相应的数据读写协议。通过系统性能分析表明,该方案具有读写高效性、存储可靠性及易于扩展等优点。
quorum-cloud:在选定的云提供商中部署Quorum网络
密钥:acmdl = 这些部分如下:仲裁系统分布式共识中的拜占庭容错分布式共识中的替代故障模型杂项未来阅读清单博客卷阅读清单学术会议和座谈会学术研讨会学术期刊和杂志 理论结果本节列出了与分布式共识相关的理论...
在一致性层面选择了基于quorum机制并且开源的braft,从协议层面来说quorum机制在延迟方面天生优于多副本强一致的方式。实现上curve对braft快照的实现进行了优化,在状态机的实现上采用chunkfilepool的方式(初始化...
肺炎克雷伯氏菌Ⅱ型群体感应系统对环境变化的响应研究,朱虎,刘慧君,本研究运用哈氏弧菌BB170报告检测和定量反转录聚合酶链式反应(qRT-PCR)技术分析了肺炎克雷伯氏菌Ⅱ型群体感应系统对环境变化(碳源
npx quorum-wizard 您还可以使用npm全局安装向导: npm install -g quorum-wizard # Once the global module is installed, run: quorum-wizard 注意:许多npm安装没有安装全局模块的权限,并且会引发EACCES错误...