
TCPCopyй°ЊеРНжАЭдєЙпЉМе∞±жШѓдЄАдЄ™еПѓдї•е∞ЖtcpжµБйЗПе§НеИґзЪДеЈ•еЕЈ(еЕґеЃЮдєЯеПѓдї•е§НеИґUDP)гАВжЬЙдЇЖињЩж†ЈдЄАдЄ™еЈ•еЕЈпЉМжИСдїђе∞±еПѓдї•зЬЯеЃЮзЪДе§НеИґзЇњдЄКжµБйЗПпЉМзДґеРОе∞ЖињЩдЇЫжµБйЗПе§НеИґеИ∞жИСдїђзЪДжµЛиѓХжЬНеК°еЩ®дЄКгАВињЩж†Је∞±еПѓдї•еЊИеЃєжШУж®°жЛЯзЇњдЄКзЬЯеЃЮзФ®жИЈзЪДиЃњйЧЃпЉМеБЪдЄАдЇЫеКЯиГљдЄКзЪДпЉМжАІиГљдЄКзЪДжµЛиѓХгАВиАМдЄФзїПињЗеЃЮйЩЕжµЛиѓХеПСзО∞TCPCopyеѓєзЇњдЄКжЬЇеЩ®зЪДиµДжЇРжґИиАЧдєЯжШѓжЮБдљОзЪДгАВ
еАЯеК©ињЩдєИдЄАдЄ™еЈ•еЕЈпЉМжИСдїђеПѓдї•жѓФиЊГеЃєжШУзЪДеЃЮзО∞дЄАдЇЫжѓФиЊГжЬЙжДПжАЭзЪДеКЯиГљгАВжѓФе¶ВжИСдїђзО∞еЬ®жИСдїђзЪДеЇФзФ®йГљеЈ≤зїПжЬНеК°еМЦдЇЖпЉМйВ£дєИжИСдїђеЬ®дЄАжђ°йЬАж±ВеПШжЫідєЛеРОпЉМжИЦиАЕдЄАжђ°жАІиГљдЉШеМЦдєЛеРОпЉМжИСдїђе¶ВдљХжЬАењЂзЪДзЯ•йБУиѓ•жЬНеК°еКЯиГљжШѓеР¶ж≠£з°ЃпЉМжАІиГљдЉШеМЦжШѓеР¶иЊЊеИ∞жЬЯжЬЫеСҐпЉЯељУзДґпЉМжИСдїђеПѓдї•дљњзФ®дЄАдЇЫжАІиГљеОЛжµЛеЈ•еЕЈж®°жЛЯе§ІйЗПиѓЈж±ВпЉМдљЖжШѓжЬЙзЪДжЧґеАЩжЭ•иЗ™зЇњдЄКзЬЯеЃЮзЪДжµБйЗПжИЦиЃЄиГљжЬАзЬЯеЃЮзЪДеПНеЇФеЃЮйЩЕжГЕеЖµгАВ
OKпЉМйВ£жИСдїђеПѓдї•дљњзФ®TCPCopyе∞ЖзЇњдЄКжµБйЗПе§НеИґеИ∞зЇњдЄЛжµЛиѓХзОѓеҐГгАВеЬ®жИСдїђдљњзФ®ињЩзІНжЦєеЉПзЪДжЧґеАЩпЉМеПИеПСзО∞еП¶е§ЦдЄАдЄ™йЧЃйҐШгАВжИСдїђеЊИе§ЪжЧґеАЩињЫи°МеЉХжµБзЪДжЧґеАЩпЉМеП™еЄМжЬЫе§НеИґйГ®еИЖжЬНеК°зЪДжµБйЗПгАВжѓФе¶ВжИСдїђжГ≥е∞ЖдЄЛеНХжЬНеК°зЪДеЉХеЕ•ињЫжЭ•пЉМдљЖеєґдЄНжГ≥е∞ЖжФѓдїШиЃҐеНХзЪДжµБйЗПдєЯеЉХеЕ•ињЫжЭ•пЉМеЫ†дЄЇињЩж†ЈжИСдїђеПѓиГљйЬАи¶БжР≠еїЇдЄАдЄ™еЊИе§НжЭВзЪДзОѓеҐГгАВеП¶е§ЦпЉМ жЬЙзЪДжЧґеАЩжИСдїђеП™жГ≥йТИеѓєеНХдЄ™жЬНеК°ињЫи°МжµЛиѓХпЉМињЩж†ЈзЪДиѓЭеП™е§НеИґеНХдЄ™жЬНеК°жИЦзђ¶еРИжЭ°дїґзЪДжµБйЗПпЉМеПѓдї•жЫіе•љзЪДйЪФз¶їжИСдїђзЪДжµЛиѓХпЉМйЪФз¶їеЕґдїЦжЬНеК°еѓєжИСдїђжµЛиѓХжЬЯжЬЫзЪДељ±еУНгАВеЯЇдЇОињЩдЇЫеОЯеЫ†пЉМжИСдїђе∞±дЄНиГљзЫіжО•зЪДе∞ЖTCPCopyзЪДжЙАжЬЙжµБйЗПеЕ®йГ®зЫіжО•зЪДеЉХеЕ•жµЛиѓХзОѓеҐГгАВдЄЇж≠§жИСдїђеЉАеПСдЇЖдЄАдЄ™proxy -- DubboCopy(еЫ†дЄЇжИСеОВзЪДжЬНеК°ж°ЖжЮґжШѓеЯЇдЇОAlibabaеЉАжЇРзЪДDubbo)гАВ
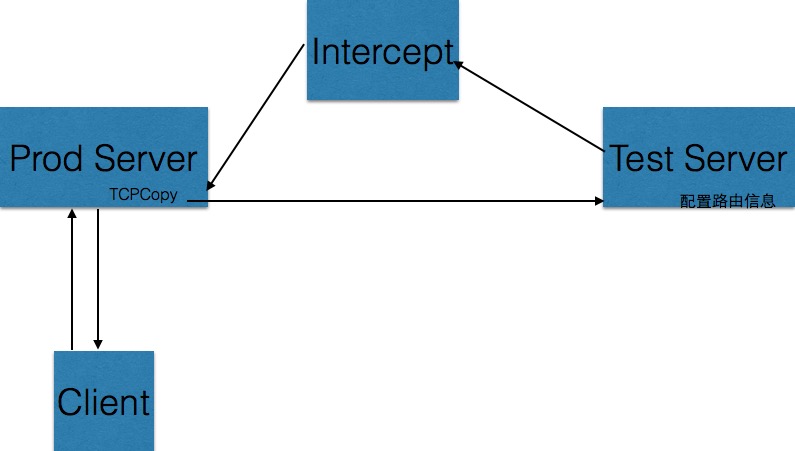
дЄЛйЭҐзђђдЄАдЄ™еЫЊжШѓдљњзФ®TCPCopyзЪДеОЯеІЛзїУжЮД:
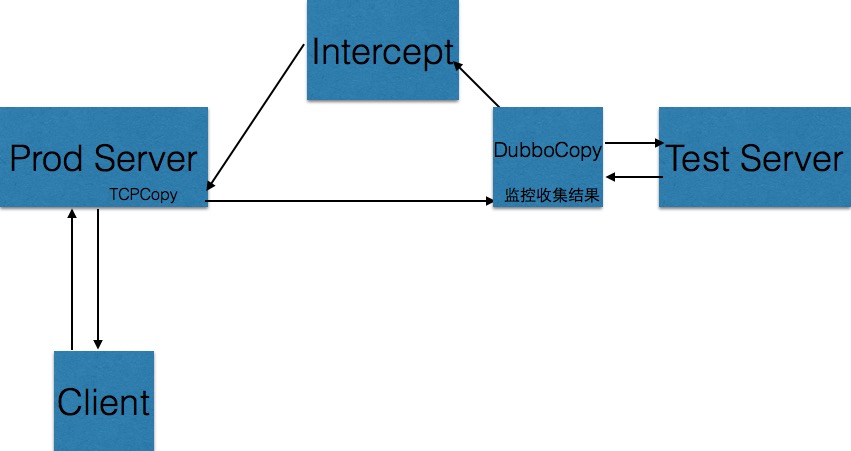
дљњзФ®DubboCopyдєЛеРОзЪДзїУжЮДпЉЪ
DubboCopyзЪДзЫЃзЪДдЄїи¶БжЬЙпЉЪ
1. йЩНдљОжЬНеК°жµБйЗПе§НеИґзЪДдљњзФ®йЧ®жІЫ
2. еЯЇдЇОе§ЪйЗНзїіеЇ¶зЪДжЬНеК°жµБйЗПе§НеИґ
3. зЫСжОІеРДзІНжАІиГљжМЗж†ЗпЉМжФґйЫЖжЬНеК°еУНеЇФзїУжЮЬ
йВ£дєИдЄЛйЭҐжИСдїђе∞±еИЖеЗ†дЄ™йГ®еИЖдїЛзїНжИСдїђжШѓе¶ВдљХеЃЮзО∞зЪДгАВ
йЩНдљОжЬНеК°жµБйЗПе§НеИґзЪДдљњзФ®йЧ®жІЫ
еЕґеЃЮTCPCopyзЪДдљњзФ®ињШжШѓжЬЙдЄАдЇЫйЧ®жІЫзЪДпЉМжЬЙдЄАдЇЫзљСжЃµзЪДйЩРеИґпЉМйЬАи¶БжЈїеК†дЄАдЇЫиЈѓзФ±и°®з≠ЙгАВеєґдЄФTCPCopyж≤°жЬЙжПРдЊЫrpmеМЕз≠ЙпЉМе¶ВжЮЬдїОйЫґжР≠еїЇдЄАе•ЧжµБйЗПе§НеИґзОѓеҐГпЉМињШжШѓи¶БиієдЄАзХ™еС®жКШгАВиАМжИСдїђжГ≥иЊЊеИ∞зЪДжШѓдЄАйФЃеЉХжµБпЉМеѓєдљњзФ®жЦєйАПжШОгАВй¶ЦеЕИжИСдїђиЗ™еЈ±buildдЇЖTCPCopyзЪДRPMжФЊеЕ•еЕђеПЄзЪДдїУеЇУгАВзДґеРОжИСдїђиѓЈж±ВOPSеНПеК©жПРдЊЫдЇЖеЬ®зЇњдЄКжЬЇеЩ®еРѓеБЬTCPCopyзЪДHTTPжО•еП£гАВињЩж†ЈдЄАжЭ•зФ®жИЈдљњзФ®иѓ•еКЯиГљзЪДжЧґеАЩпЉМе∞±еЯЇжЬђдЄКжДЯеПЧдЄНеИ∞TCPCopyзЪДе≠ШеЬ®гАВињЩйЗМиѓізВєйҐШе§ЦиѓЭпЉЪгАОеЯЇз°АиЃЊжЦљжЬНеК°еМЦпЉМжµБз®ЛAPIеМЦгАПжШѓжПРйЂШзФЯдЇІжХИзОЗйЭЮеЄЄжЬЙжХИзЪДеКЮж≥ХпЉМжДЯи∞ҐеЕДеЉЯйГ®йЧ®зЪДеНПдљЬиЃ©жХідЄ™жµБз®ЛзХЕйАЪиµЈжЭ•гАВ
еП¶е§ЦдЄАзВєжШѓпЉМеЫ†дЄЇTCPCopyзЫіжО•йЭҐеѓєзЪДжШѓжИСдїђжПРдЊЫзЪДињЩдЄ™proxyпЉМдЄНдЉЪзЫіжО•иЈЯзЇњдЄЛжµЛиѓХжЬНеК°еЩ®дЇ§дЇТпЉМжЙАдї•дЄАдЇЫйЕНзљЃеЬ®proxyдЄКйЕНзљЃпЉМдєЯеѓєдљњзФ®иАЕйАПжШОпЉМзїІзї≠йЩНдљОдЇЖдљњзФ®зЪДе§НжЭВеЇ¶гАВ
еПѓдї•еЯЇдЇОе§ЪйЗНзїіеЇ¶зЪДжЬНеК°жµБйЗПе§НеИґ
ињЩдЄАзВєжШѓжИСдїђзЪДдЄїи¶БзЫЃзЪДгАВзФ®жИЈдљњзФ®иѓ•еКЯиГљзЪДжЧґеАЩпЉМеП™йЬАи¶БеЬ®зХМйЭҐдЄКйАЙжЛ©йЬАи¶Бе§НеИґзЪДжЬНеК°пЉМеєґдЄФжМЗеЃЪзЫЃж†ЗжЬЇеЩ®гАВињЩжЧґDubboCopyе∞±дЉЪдљњзФ®и∞ГзФ®жО•еП£еЬ®зЇњдЄКжЬЇеЩ®еРѓеК®TCPCopyгАВйЬАи¶Бж≥®жДПзЪДжШѓпЉМжИСдїђе§НеИґзЪДжµБйЗПеПѓиГљжЭ•иЗ™зЇњдЄКе§ЪеП∞жЬЇеЩ®пЉМиАМжИСдїђзЪДDubboCopyдєЯжШѓйГ®зљ≤жЬЙе§ЪеП∞гАВйВ£дєИеЬ®и∞ГзФ®еРѓеК®жО•еП£зЪДжЧґеАЩпЉМдЉЪдљњзФ®з±їдЉЉдЄАдЄ™иіЯиљљеЭЗи°°зЪДжЦєеЉПеПСйАБдЄНеРМзЪДеСљдї§еИ∞дЄНеРМзЪДзЇњдЄКжЬЇеЩ®пЉМе∞ЖжµБйЗПеЭЗи°°зЪДе§НеИґеИ∞еРДдЄ™DubboCopyгАВ
ељУTCPCopyе∞ЖжµБйЗПе§НеИґеИ∞proxyеРОпЉМжИСдїђеПѓдї•йГ®еИЖиІ£жЮРDubboзЪДеНПиЃЃпЉМдїОдЄ≠жПРеПЦеЗЇжЬНеК°пЉМжЦєж≥Хз≠Йдњ°жБѓгАВжЬЙдЇЖињЩдЇЫдњ°жБѓжИСдїђе∞±еПѓдї•ж†єжНЃйҐДеЕИйЕНзљЃе•љзЪДдњ°жБѓйАЙжЛ©и¶Бе∞ЖжХ∞жНЃеМЕе§НеИґеИ∞еУ™дЇЫжµЛиѓХжЬЇгАВDubboCopyжШѓдљњзФ®NettyеЉАеПСзЪДпЉМжО•жФґеИ∞TCPCopyе§НеИґињЗжЭ•зЪДжµБйЗПдєЛеРОпЉМжИСдїђйГ®еИЖзЪДиІ£жЮРеЗЇжЙАйЬАдњ°жБѓпЉМзДґеРОдЇЖиІ£еИ∞иѓ•иѓЈж±ВзЪДйХњеЇ¶пЉМиѓїеПЦжМЗеЃЪйХњеЇ¶зЪДжХ∞жНЃпЉМзДґеРОеПСйАБеИ∞зЫЃж†ЗжЬЇгАВдљЖжШѓпЉМе¶ВжЮЬжИСдїђжГ≥жПРдЊЫињЩж†ЈдЄАдЄ™йАЪзФ®жЬНеК°пЉМжИСдїђйЬАи¶БжЙњиљље§ІйЗПзЇњдЄКжЬЇеЩ®е§НеИґињЗжЭ•зЪДжµБйЗПпЉМдљЖжШѓеЯЇдЇОжИРжЬђиАГиЩСжИСдїђзЪДDubboCopyдЄНиГљжЙ©е±ХзЙєеИЂе§ЪгАВйВ£дєИжИСдїђжАОдєИжЫіжЬЙжХИзОЗзЪДе§ДзРЖињЩдЄ™иљђеПСеСҐпЉЯеѓєдЇОињЩж†ЈдЄАдЄ™зљСзїЬиљђеПСеЇФзФ®иАМи®АпЉМжИСдїђзЪДиµДжЇРжґИиАЧдЄїи¶БеЬ®зљСзїЬпЉМеЖЕе≠ШеТМCPUгАВеЖЕзљСйЗМпЉМдЄАиИђжЭ•иѓізљСзїЬдЄНдЉЪжИРдЄЇдЄАдЄ™зЙєеИЂе§ІзЪДйЧЃйҐШпЉМиАМдЄФе§ІйГ®еИЖдЄЪеК°жЬНеК°пЉМжХ∞жНЃйЗПеєґдЄНжШѓзЙєеИЂе§І(ељУзДґдєЯжЬЙдЄАдЇЫжШѓйЬАи¶БиОЈеПЦе§ІйЗПзЪДжХ∞жНЃ)гАВCPUдЄїи¶БзФ®дЇОе§ДзРЖзљСзїЬеТМеНПиЃЃиІ£жЮРйГ®еИЖгАВиАМдљњзФ®JavaзЉЦеЖЩињЩз±їжЬНеК°пЉМжИСжЬАжЛЕењГзЪДжШѓеЖЕе≠ШдЄКгАВеЫ†дЄЇиѓ•жЬНеК°йЬАи¶Бе§ДзРЖе§ІйЗПзЪДиѓЈж±ВжХ∞жНЃпЉМGCдЉЪдЄНдЉЪжИРдЄЇдЄАдЄ™еЊИе§ІзЪДйЧЃйҐШеСҐпЉЯдЄНињЗињЫдЄАж≠•еИЖжЮРжИСдїђеПСзО∞пЉМеПѓдї•еБЪеИ∞еЗ†дєОдЄНдљњзФ®е†ЖеЖЕе≠ШгАВNettyиѓїеПЦзЪДжХ∞жНЃеПѓдї•дљњзФ®DirectByteBufferпЉМињЩж†Је∞±еИЖйЕНеЬ®е†Же§ЦдЇЖпЉМзДґеРОжИСдїђдєЯжШѓйГ®еИЖиІ£жЮРиѓЈж±ВзЪДжХ∞жНЃпЉМињЩеП™дЉЪеН†зФ®еЊИе∞СзЪДе≠ЧиКВгАВеП¶е§ЦпЉМжИСдїђжПРеПЦзЪДдњ°жБѓеЕґеЃЮйГљжШѓз±їдЉЉжЬНеК°еРНпЉМжЦєж≥ХеРНз≠ЙеЕГжХ∞жНЃдњ°жБѓгАВеѓєдЇОињЩз±їдњ°жБѓжИСдїђйГљжШѓеПѓдї•зЉУе≠ШзЪДгАВиАМжХ∞жНЃеСҐпЉЯеЕґеЃЮжИСдїђеП™йЬАи¶Бз°ЃеЃЪдЄАдЄ™иѓЈж±ВзЪДжХ∞жНЃе§Іе∞ПпЉМзДґеРОе∞ЖињЩдЄ™е§Іе∞ПзЪДжХ∞жНЃеОЯж†ЈзЪДе§НеИґињЗеОїеН≥еПѓгАВжИСдїђдљњзФ®NettyзЪДByteBufзЪДreadSliceпЉМзФЪиЗ≥йГљжЧ†й°їе∞ЖжХ∞жНЃиѓїеПЦеЗЇжЭ•пЉМе∞±еПѓдї•зЫіжО•е∞ЖжЙАйЬАжХ∞жНЃеЖЩеЕ•еИ∞еПСйАБйАЪйБУгАВињЩж†ЈжХідЄ™ињЗз®ЛпЉМеЯЇжЬђдЄКжШѓдЄНжАОдєИжґИиАЧе†ЖеЖЕеЖЕе≠ШзЪДпЉМжЙАдї•GCеЯЇжЬђдЄКж≤°жЬЙеОЛеКЫгАВиАМеѓєдЇОе†Же§ЦеЖЕе≠ШпЉМNetty 4жПРдЊЫдЇЖpoolпЉМдєЯиГље§Іе§ІйЩНдљОеИЖйЕНзЪДеЉАйФАгАВеЬ®жИСдїђзЪДеЃЮйЩЕжµЛиѓХдєЯи°®жШОдЇЖе†ЖеЖЕе≠ШеН†зФ®жЮБдљОпЉМGCдєЯдЄНжАОдєИйҐСзєБгАВ
еП¶е§ЦпЉМжИСдїђе∞ЖжО•еПЧжХ∞жНЃзЪДNetty ServerзЪДworkerзЇњз®ЛдЄОеПСйАБжХ∞жНЃзЪДNetty ClientзЪДworkerзЇњз®ЛињЫи°МеЕ±дЇЂпЉМињЩж†ЈињЫдЄАж≠•йЩНдљОдЇЖдЄКдЄЛжЦЗеИЗжНҐзЪДйҐСзОЗгАВ
зЫСжОІеРДзІНжАІиГљжМЗж†ЗпЉМжФґйЫЖжЬНеК°еУНеЇФзїУжЮЬ
еЃЮйЩЕдЄКпЉМжИСдїђињЫи°Ме§НеИґзЪДзЫЃзЪДжЧ†йЭЮе∞±дЄ§зВєпЉЪжАІиГљжµЛиѓХеТМеКЯиГљжµЛиѓХгАВ
йВ£дєИеѓєдЇОжАІиГљжµЛиѓХжЭ•иѓіе∞±жШѓеРДзІНжАІиГљжМЗж†ЗпЉМиАМжЬНеК°зЪДRTжШѓеР¶жЬЙеПШеМЦеПѓиГљжШѓеЕґдЄ≠жЬАеЕ≥йФЃзЪДдЄАзВєгАВ
еѓєдЇОеКЯиГљжµЛиѓХпЉМжЬАзЫіжО•зЪДеПѓиГљжШѓжЬНеК°зЪДеУНеЇФжХ∞жНЃжШѓеР¶жЬЙеЉВеЄЄз≠ЙпЉМдЄНињЗдєЯеПѓдї•ињЫдЄАж≠•еБЪеИ∞еУНеЇФжХ∞жНЃдЄОзЇњдЄКжЬНеК°зЪДеУНеЇФжХ∞жНЃињЫи°МеѓєжѓФ(ињЩдЄАзВєзЫЃеЙНињШжЬ™еЃЮзО∞)гАВ
жЬЙдЇЖињЩдЄ§жЦєйЭҐзЪДжХ∞жНЃпЉМжИСдїђе∞±и¶ЖзЫЦдЇЖжЬНеК°жµБйЗПе§НеИґеИ∞зїУжЮЬжФґйЫЖдЄ§дЄ™зОѓиКВпЉМиГљеБЪеИ∞дЄАдЄ™жѓФиЊГжЬЙжХИзЪДзЇњдЄКзОѓеҐГж®°жЛЯзЪДеЈ•еЕЈдЇЖгАВ
йВ£дєИйЧЃйҐШжЭ•дЇЖпЉМе§ІеЃґзЪДзЇњдЄКж®°жЛЯзОѓеҐГжШѓжАОдєИеЃЮзО∞зЪДеСҐпЉЯжИЦиАЕеѓєињЩдЄ™еЈ•еЕЈжДЯеЕіиґ£пЉМжЬЙдїАдєИжЦ∞йЬАж±ВзЪДйÚ搥ињОжЭ•иБКиБКгАВ
 
http://www.cnblogs.com/yuyijq/p/4541660.html



зЫЄеЕ≥жО®иНР
е§ІжХ∞жНЃжКАжЬѓжМЗзЪДжШѓзФ®дЇОе§ДзРЖеТМеИЖжЮРе§ІиІДж®°жХ∞жНЃйЫЖзЪДжКАжЬѓеТМеЈ•еЕЈгАВдї•дЄЛжШѓдЄАдЇЫеЄЄиІБзЪДе§ІжХ∞жНЃжКАжЬѓеТМеЈ•еЕЈпЉЪ HadoopпЉЪApache HadoopжШѓдЄАдЄ™зФ®дЇОеИЖеЄГеЉПе≠ШеВ®еТМе§ДзРЖе§ІиІДж®°жХ∞жНЃзЪДеЉАжЇРж°ЖжЮґгАВеЃГеМЕжЛђHadoop Distributed File SystemпЉИHDFSпЉЙзФ®дЇОжХ∞жНЃе≠ШеВ®еТМMapReduceзФ®дЇОжХ∞жНЃе§ДзРЖгАВ SparkпЉЪApache SparkжШѓдЄАдЄ™ењЂйАЯгАБйАЪзФ®зЪДйЫЖзЊ§иЃ°зЃЧз≥їзїЯпЉМжПРдЊЫдЇЖжѓФMapReduceжЫіењЂзЪДжХ∞жНЃе§ДзРЖиГљеКЫгАВеЃГжФѓжМБеЖЕе≠ШиЃ°зЃЧеТМжЫіе§Ъе§НжЭВзЪДжХ∞жНЃе§ДзРЖжµБз®ЛгАВ NoSQLжХ∞жНЃеЇУпЉЪNoSQLжХ∞жНЃеЇУпЉИе¶ВMongoDBгАБCassandraз≠ЙпЉЙеИЩжЫійАВзФ®дЇОе§ДзРЖињЩз±їжХ∞жНЃгАВ жХ∞жНЃдїУеЇУпЉЪжХ∞жНЃдїУеЇУжШѓдЄАдЄ™зФ®дЇОйЫЖжИРеТМеИЖжЮРе§ІиІДж®°жХ∞жНЃзЪДе≠ШеВ®з≥їзїЯпЉМдЄАдЇЫзЯ•еРНзЪДжХ∞жНЃдїУеЇУеМЕжЛђSnowflakeгАБAmazon Redshiftз≠ЙгАВ жХ∞жНЃжєЦпЉЪжХ∞жНЃжєЦжШѓдЄАдЄ™е≠ШеВ®зїУжЮДеМЦеТМйЭЮзїУжЮДеМЦжХ∞жНЃзЪДе≠Ше®汆пЉМзФ®дЇОжФѓжМБжХ∞жНЃеИЖжЮРеТМжЬЇеЩ®е≠¶дє†еЇФзФ®гАВ жЬЇеЩ®е≠¶дє†пЉЪе§ІжХ∞жНЃжКАжЬѓдєЯеєњж≥ЫеЇФзФ®дЇОжЬЇеЩ®е≠¶дє†йҐЖеЯЯпЉМжФѓжМБе§ІиІДж®°жХ∞жНЃзЪДж®°еЮЛиЃ≠зїГеТМйҐДжµЛеИЖжЮРгАВ жµБеЉПе§ДзРЖпЉЪйТИеѓєеЃЮжЧґжХ∞жНЃе§ДзРЖйЬАж±ВпЉМжµБеЉПе§ДзРЖжКАжЬѓпЉИе¶ВApache KafkaгАБApache FlinkпЉЙеПѓдї•еЃЮжЧґгАВ
еАНз¶ПGSDML-V2.31-Pepperl+Fuchs-PxV100-20210104.xml
е§ІжХ∞жНЃжКАжЬѓжМЗзЪДжШѓзФ®дЇОе§ДзРЖеТМеИЖжЮРе§ІиІДж®°жХ∞жНЃйЫЖзЪДжКАжЬѓеТМеЈ•еЕЈгАВдї•дЄЛжШѓдЄАдЇЫеЄЄиІБзЪДе§ІжХ∞жНЃжКАжЬѓеТМеЈ•еЕЈпЉЪ HadoopпЉЪApache HadoopжШѓдЄАдЄ™зФ®дЇОеИЖеЄГеЉПе≠ШеВ®еТМе§ДзРЖе§ІиІДж®°жХ∞жНЃзЪДеЉАжЇРж°ЖжЮґгАВеЃГеМЕжЛђHadoop Distributed File SystemпЉИHDFSпЉЙзФ®дЇОжХ∞жНЃе≠ШеВ®еТМMapReduceзФ®дЇОжХ∞жНЃе§ДзРЖгАВ SparkпЉЪApache SparkжШѓдЄАдЄ™ењЂйАЯгАБйАЪзФ®зЪДйЫЖзЊ§иЃ°зЃЧз≥їзїЯпЉМжПРдЊЫдЇЖжѓФMapReduceжЫіењЂзЪДжХ∞жНЃе§ДзРЖиГљеКЫгАВеЃГжФѓжМБеЖЕе≠ШиЃ°зЃЧеТМжЫіе§Ъе§НжЭВзЪДжХ∞жНЃе§ДзРЖжµБз®ЛгАВ NoSQLжХ∞жНЃеЇУпЉЪNoSQLжХ∞жНЃеЇУпЉИе¶ВMongoDBгАБCassandraз≠ЙпЉЙеИЩжЫійАВзФ®дЇОе§ДзРЖињЩз±їжХ∞жНЃгАВ жХ∞жНЃдїУеЇУпЉЪжХ∞жНЃдїУеЇУжШѓдЄАдЄ™зФ®дЇОйЫЖжИРеТМеИЖжЮРе§ІиІДж®°жХ∞жНЃзЪДе≠ШеВ®з≥їзїЯпЉМдЄАдЇЫзЯ•еРНзЪДжХ∞жНЃдїУеЇУеМЕжЛђSnowflakeгАБAmazon Redshiftз≠ЙгАВ жХ∞жНЃжєЦпЉЪжХ∞жНЃжєЦжШѓдЄАдЄ™е≠ШеВ®зїУжЮДеМЦеТМйЭЮзїУжЮДеМЦжХ∞жНЃзЪДе≠Ше®汆пЉМзФ®дЇОжФѓжМБжХ∞жНЃеИЖжЮРеТМжЬЇеЩ®е≠¶дє†еЇФзФ®гАВ жЬЇеЩ®е≠¶дє†пЉЪе§ІжХ∞жНЃжКАжЬѓдєЯеєњж≥ЫеЇФзФ®дЇОжЬЇеЩ®е≠¶дє†йҐЖеЯЯпЉМжФѓжМБе§ІиІДж®°жХ∞жНЃзЪДж®°еЮЛиЃ≠зїГеТМйҐДжµЛеИЖжЮРгАВ жµБеЉПе§ДзРЖпЉЪйТИеѓєеЃЮжЧґжХ∞жНЃе§ДзРЖйЬАж±ВпЉМжµБеЉПе§ДзРЖжКАжЬѓпЉИе¶ВApache KafkaгАБApache FlinkпЉЙеПѓдї•еЃЮжЧґгАВ
Java SSMй°єзЫЃжШѓдЄАзІНдљњзФ®Javaиѓ≠и®АеТМSSMж°ЖжЮґпЉИSpring + Spring MVC + MyBatisпЉЙеЉАеПСзЪДWebеЇФзФ®з®ЛеЇПгАВSSMжШѓдЄАзІНеЄЄзФ®зЪДJavaеЉАеПСж°ЖжЮґзїДеРИпЉМеЃГзїУеРИдЇЖSpringж°ЖжЮґгАБSpring MVCж°ЖжЮґеТМMyBatisж°ЖжЮґзЪДдЉШзВєпЉМиГље§ЯењЂйАЯжЮДеїЇеПѓйЭ†гАБйЂШжХИзЪДдЉБдЄЪзЇІеЇФзФ®гАВ 1. Springж°ЖжЮґпЉЪSpringжШѓдЄАдЄ™иљїйЗПзЇІзЪДJavaеЉАеПСж°ЖжЮґпЉМжПРдЊЫдЇЖдЄ∞еѓМзЪДеКЯиГљеТМж®°еЭЧпЉМзФ®дЇОеЉАеПСдЉБдЄЪзЇІеЇФзФ®гАВеЃГеМЕжЛђIoCпЉИInverse of ControlпЉМжОІеИґеПНиљђпЉЙеЃєеЩ®гАБAOPпЉИAspect-Oriented ProgrammingпЉМйЭҐеРСеИЗйЭҐзЉЦз®ЛпЉЙз≠ЙзЙєжАІпЉМеПѓдї•зЃАеМЦеЉАеПСињЗз®ЛгАБжПРйЂШдї£з†БзЪДеПѓзїіжК§жАІеТМеПѓжµЛиѓХжАІгАВ 2. Spring MVCж°ЖжЮґпЉЪSpring MVCжШѓеЯЇдЇОSpringж°ЖжЮґзЪДWebж°ЖжЮґпЉМзФ®дЇОеЉАеПСWebеЇФзФ®з®ЛеЇПгАВеЃГйЗЗзФ®MVCпЉИModel-View-ControllerпЉМж®°еЮЛ-иІЖеЫЊ-жОІеИґеЩ®пЉЙзЪДжЮґжЮДж®°еЉПпЉМе∞ЖеЇФзФ®з®ЛеЇПеИЖдЄЇж®°еЮЛе±ВгАБиІЖеЫЊе±ВеТМжОІеИґеЩ®е±ВпЉМжПРдЊЫдЇЖе§ДзРЖиѓЈж±ВгАБжЄ≤жЯУиІЖеЫЊеТМзЃ°зРЖжµБз®ЛзЪДеКЯиГљгАВ 3. MyBatisж°ЖжЮґпЉЪMyBatisжШѓдЄАдЄ™жМБдєЕе±Вж°ЖжЮґпЉМзФ®дЇОдЄОжХ∞жНЃеЇУињЫи°МдЇ§дЇТгАВеЃГжПРдЊЫдЇЖдЄАзІНе∞ЖжХ∞жНЃеЇУжУНдљЬдЄОJavaеѓєи±°жШ†е∞ДиµЈжЭ•зЪДжЦєеЉПпЉМйБњеЕНдЇЖжЙЛеК®зЉЦеЖЩзєБзРРзЪДSQLиѓ≠еП•пЉМеєґжПРдЊЫдЇЖдЇЛеК°зЃ°зРЖеТМзЉУе≠Шз≠ЙеКЯиГљпЉМзЃАеМЦдЇЖжХ∞жНЃеЇУиЃњйЧЃзЪДињЗз®Л
Java SSMй°єзЫЃжШѓдЄАзІНдљњзФ®Javaиѓ≠и®АеТМSSMж°ЖжЮґпЉИSpring + Spring MVC + MyBatisпЉЙеЉАеПСзЪДWebеЇФзФ®з®ЛеЇПгАВSSMжШѓдЄАзІНеЄЄзФ®зЪДJavaеЉАеПСж°ЖжЮґзїДеРИпЉМеЃГзїУеРИдЇЖSpringж°ЖжЮґгАБSpring MVCж°ЖжЮґеТМMyBatisж°ЖжЮґзЪДдЉШзВєпЉМиГље§ЯењЂйАЯжЮДеїЇеПѓйЭ†гАБйЂШжХИзЪДдЉБдЄЪзЇІеЇФзФ®гАВ 1. Springж°ЖжЮґпЉЪSpringжШѓдЄАдЄ™иљїйЗПзЇІзЪДJavaеЉАеПСж°ЖжЮґпЉМжПРдЊЫдЇЖдЄ∞еѓМзЪДеКЯиГљеТМж®°еЭЧпЉМзФ®дЇОеЉАеПСдЉБдЄЪзЇІеЇФзФ®гАВеЃГеМЕжЛђIoCпЉИInverse of ControlпЉМжОІеИґеПНиљђпЉЙеЃєеЩ®гАБAOPпЉИAspect-Oriented ProgrammingпЉМйЭҐеРСеИЗйЭҐзЉЦз®ЛпЉЙз≠ЙзЙєжАІпЉМеПѓдї•зЃАеМЦеЉАеПСињЗз®ЛгАБжПРйЂШдї£з†БзЪДеПѓзїіжК§жАІеТМеПѓжµЛиѓХжАІгАВ 2. Spring MVCж°ЖжЮґпЉЪSpring MVCжШѓеЯЇдЇОSpringж°ЖжЮґзЪДWebж°ЖжЮґпЉМзФ®дЇОеЉАеПСWebеЇФзФ®з®ЛеЇПгАВеЃГйЗЗзФ®MVCпЉИModel-View-ControllerпЉМж®°еЮЛ-иІЖеЫЊ-жОІеИґеЩ®пЉЙзЪДжЮґжЮДж®°еЉПпЉМе∞ЖеЇФзФ®з®ЛеЇПеИЖдЄЇж®°еЮЛе±ВгАБиІЖеЫЊе±ВеТМжОІеИґеЩ®е±ВпЉМжПРдЊЫдЇЖе§ДзРЖиѓЈж±ВгАБжЄ≤жЯУиІЖеЫЊеТМзЃ°зРЖжµБз®ЛзЪДеКЯиГљгАВ 3. MyBatisж°ЖжЮґпЉЪMyBatisжШѓдЄАдЄ™жМБдєЕе±Вж°ЖжЮґпЉМзФ®дЇОдЄОжХ∞жНЃеЇУињЫи°МдЇ§дЇТгАВеЃГжПРдЊЫдЇЖдЄАзІНе∞ЖжХ∞жНЃеЇУжУНдљЬдЄОJavaеѓєи±°жШ†е∞ДиµЈжЭ•зЪДжЦєеЉПпЉМйБњеЕНдЇЖжЙЛеК®зЉЦеЖЩзєБзРРзЪДSQLиѓ≠еП•пЉМеєґжПРдЊЫдЇЖдЇЛеК°зЃ°зРЖеТМзЉУе≠Шз≠ЙеКЯиГљпЉМзЃАеМЦдЇЖжХ∞жНЃеЇУиЃњйЧЃзЪДињЗз®Л
Node.jsпЉМзЃАзІ∞NodeпЉМжШѓдЄАдЄ™еЉАжЇРдЄФиЈ®еє≥еП∞зЪДJavaScriptињРи°МжЧґзОѓеҐГпЉМеЃГеЕБиЃЄеЬ®жµПиІИеЩ®е§ЦињРи°МJavaScriptдї£з†БгАВNode.jsдЇО2009еєізФ±Ryan DahlеИЫзЂЛпЉМжЧ®еЬ®еИЫеїЇйЂШжАІиГљзЪДWebжЬНеК°еЩ®еТМзљСзїЬеЇФзФ®з®ЛеЇПгАВеЃГеЯЇдЇОGoogle ChromeзЪДV8 JavaScriptеЉХжУОпЉМеПѓдї•еЬ®WindowsгАБLinuxгАБUnixгАБMac OS Xз≠ЙжУНдљЬз≥їзїЯдЄКињРи°МгАВ Node.jsзЪДзЙєзВєдєЛдЄАжШѓдЇЛдїґй©±еК®еТМйЭЮйШїе°ЮI/Oж®°еЮЛпЉМињЩдљњеЊЧеЃГйЭЮеЄЄйАВеРИе§ДзРЖе§ІйЗПеєґеПСињЮжО•пЉМдїОиАМеЬ®жЮДеїЇеЃЮжЧґеЇФзФ®з®ЛеЇПе¶ВеЬ®зЇњжЄЄжИПгАБиБК姩еЇФзФ®дї•еПКеЃЮжЧґйАЪиЃѓжЬНеК°жЧґи°®зО∞еНУиґКгАВж≠§е§ЦпЉМNode.jsдљњзФ®дЇЖж®°еЭЧеМЦзЪДжЮґжЮДпЉМйАЪињЗnpmпЉИNode package managerпЉМNodeеМЕзЃ°зРЖеЩ®пЉЙ,з§ЊеМЇжИРеСШеПѓдї•еЕ±дЇЂеТМе§НзФ®дї£з†БпЉМжЮБе§ІеЬ∞дњГињЫдЇЖNode.jsзФЯжАБз≥їзїЯзЪДеПСе±ХеТМжЙ©еЉ†гАВ Node.jsдЄНдїЕзФ®дЇОжЬНеК°еЩ®зЂѓеЉАеПСгАВйЪПзЭАжКАжЬѓзЪДеПСе±ХпЉМеЃГдєЯ襀зФ®дЇОжЮДеїЇеЈ•еЕЈйУЊгАБеЉАеПСж°МйЭҐеЇФзФ®з®ЛеЇПгАБзЙ©иБФзљСиЃЊе§Зз≠ЙгАВNode.jsиГље§Яе§ДзРЖжЦЗдїґз≥їзїЯгАБжУНдљЬжХ∞жНЃеЇУгАБе§ДзРЖзљСзїЬиѓЈж±Вз≠ЙпЉМеЫ†ж≠§пЉМеЉАеПСиАЕеПѓдї•зФ®JavaScriptзЉЦеЖЩеЕ®ж†ИеЇФзФ®з®ЛеЇПпЉМињЩдЄАзВєе§Іе§ІжПРйЂШдЇЖеЉАеПСжХИзОЗеТМдЊњжНЈжАІгАВ еЬ®еЃЮиЈµдЄ≠пЉМиЃЄе§Ъе§ІеЮЛдЉБдЄЪеТМзїДзїЗеЈ≤зїПйЗЗзФ®Node.jsдљЬдЄЇеЕґWebеЇФзФ®з®ЛеЇПзЪДеЉАеПСеє≥еП∞пЉМе¶ВNetflixгАБPayPalеТМWalmartз≠ЙгАВеЃГдїђеИ©зФ®Node.jsжПРйЂШдЇЖеЇФзФ®жАІиГљпЉМзЃАеМЦдЇЖеЉАеПСжµБз®ЛпЉМеєґдЄФиГљжЫіењЂеЬ∞еУНеЇФеЄВеЬЇйЬАж±ВгАВ
еЃЙеЕ®еЃЮиЈµ-еЈ•дЄЪдЇТиБФзљСеЃЙеЕ®еЃЮиЈµдЄОиґЛеКњеИЖжЮРdr.pptx
дЇЇеЈ•жЩЇиГљпЉИAIпЉЙзЪДжЉФињЫдЄОеЇФзФ®жШѓдЄАдЄ™иЈ®иґКжХ∞еНБеєізЪДеОЖз®ЛпЉМеЃГдЄНдїЕжФєеПШдЇЖжИСдїђзЪДжКАжЬѓжЩѓиІВпЉМдєЯжЈ±еИїељ±еУНдЇЖжИСдїђзЪДжЧ•еЄЄзФЯжіїгАВPPTиѓ¶зїЖдїЛзїНдЇЖAIзЪДеОЖеП≤дЄОжЉФеПШгАБAIжКАжЬѓзЪДеЇФзФ®зО∞зКґгАБAIдЉ¶зРЖгАБеЃЙеЕ®дЄОз§ЊдЉЪиі£дїїгАБAIзЪДжЬ™жЭ•еПСе±ХиґЛеКњгАБAIжЬ™жЭ•еПСе±ХеѓєдЇЇдїђзФЯжіїзЪДеРДзІНељ±еУНгАВ жΥ糥AIзЪДеОЖеП≤жЄКжЇРпЉМеЃ°иІЖеЕґељУеЙНеЇФзФ®йҐЖеЯЯзЪДзО∞зКґпЉМжАЭиАГAIдЉ¶зРЖгАБеЃЙеЕ®дЄОз§ЊдЉЪиі£дїїз≠ЙйЗНи¶БиЃЃйҐШпЉМдї•еПКе±ХжЬЫAIзЪДжЬ™жЭ•еПСе±ХиґЛеКњгАВжЬАеРОпЉМжИСдїђе∞ЖеЕ±еРМжОҐиЃ®AIдЄОдЇЇз±їеЕ±зФЯзЪДжЬ™жЭ•еПѓиГљжАІгАВAIдЄОдЇЇз±їе∞ЖеЕ±зФЯеЕ±еИЫзЊОе•љжЬ™жЭ• AIзЪДиЃ≠зїГж®°еЉПдЄОжКАжЬѓињЫж≠•пЉМжО®еК®дЇЖAIзЪДењЂйАЯеПСе±ХеТМеЇФзФ®гАВ AIжКАжЬѓзЪДеЇФзФ®зО∞зКґеєњж≥ЫиАМжЈ±еЕ•пЉМжґµзЫЦдЇЖеМїзЦЧеБ•еЇЈгАБжХЩиВ≤гАБдЇ§йАЪдЄОеЯОеЄВиІДеИТдї•еПКеИЫжДПдЇІдЄЪз≠Йе§ЪдЄ™йҐЖеЯЯгАВ
LжЦЗдЄїи¶БжШѓеѓєдЇМжЙЛжЙЛжЬЇеЫЮжФґеє≥еП∞з≥їзїЯињЫи°МдЇЖдїЛзїНпЉМеМЕжЛђз†Фз©ґзЪДзО∞зКґпЉМињШжЬЙжґЙеПКзЪДеЉАеПСиГМжЩѓпЉМзДґеРОињШеѓєз≥їзїЯзЪДиЃЊиЃ°зЫЃж†ЗињЫи°МдЇЖиЃЇињ∞пЉМињШжЬЙз≥їзїЯзЪДйЬАж±ВпЉМдї•еПКжХідЄ™зЪДиЃЊиЃ°жЦєж°ИпЉМеѓєз≥їзїЯзЪДиЃЊиЃ°дї•еПКеЃЮзО∞пЉМдєЯйГљиЃЇињ∞зЪДжѓФиЊГзїЖиЗіпЉМжЬАеРОеѓєдЇМжЙЛжЙЛжЬЇеЫЮжФґеє≥еП∞з≥їзїЯињЫи°МдЇЖдЄАдЇЫеЕЈдљУжµЛиѓХгАВ жЬђжЦЗдї•JavaдЄЇеЉАеПСжКАжЬѓпЉМеЃЮзО∞дЇЖдЄАдЄ™дЇМжЙЛжЙЛжЬЇеЫЮжФґеє≥еП∞з≥їзїЯгАВдЇМжЙЛжЙЛжЬЇеЫЮжФґеє≥еП∞з≥їзїЯзЪДдЄїи¶БдљњзФ®иАЕеИЖдЄЇзЃ°зРЖеСШпЉЫдЄ™дЇЇдЄ≠ењГгАБзФ®жИЈзЃ°зРЖгАБжЙЛжЬЇеУБзЙМзЃ°зРЖгАБжЙЛжЬЇеХЖеЯОзЃ°зРЖгАБжЙЛжЬЇеЫЮжФґзЃ°зРЖгАБжЙЛжЬЇдЉ∞дїЈзЃ°зРЖгАБз≥їзїЯзЃ°зРЖгАБиЃҐеНХзЃ°зРЖпЉМеЙНеП∞й¶Цй°µпЉЫй¶Цй°µгАБжЙЛжЬЇеХЖеЯОгАБжЦ∞йЧїиµДиЃѓгАБжИСзЪДгАБиЈ≥иљђеИ∞еРОеП∞гАБиі≠зЙ©иљ¶пЉМзФ®жИЈпЉЫдЄ™дЇЇдЄ≠ењГгАБжЙЛжЬЇеЫЮжФґзЃ°зРЖгАБжЙЛжЬЇдЉ∞дїЈзЃ°зРЖгАБжИСзЪДжФґиЧПзЃ°зРЖгАБиЃҐеНХзЃ°зРЖз≠ЙеКЯиГљгАВйАЪињЗињЩдЇЫеКЯиГљж®°еЭЧзЪДиЃЊиЃ°пЉМеЯЇжЬђдЄКеЃЮзО∞дЇЖжХідЄ™дЇМжЙЛжЙЛжЬЇеЫЮжФґеє≥еП∞з≥їзїЯзЪДињЗз®ЛгАВ еЕЈдљУеЬ®з≥їзїЯиЃЊиЃ°дЄКпЉМйЗЗзФ®дЇЖB/SзЪДзїУжЮДпЉМеРМжЧґпЉМдєЯдљњзФ®JavaжКАжЬѓеЬ®еК®жАБй°µйЭҐдЄКињЫи°МдЇЖиЃЊиЃ°пЉМеРОеП∞дЄКйЗЗзФ®MysqlжХ∞жНЃеЇУпЉМжШѓдЄАдЄ™йЭЮеЄЄдЉШзІАзЪДдЇМжЙЛжЙЛжЬЇеЫЮжФґеє≥еП∞з≥їзїЯгАВ еЕ≥йФЃиѓН пЉЪдЇМжЙЛжЙЛжЬЇеЫЮжФґеє≥еП∞з≥їзїЯпЉЫJavaжКАжЬѓпЉЫMysqlжХ∞жНЃеЇУпЉЫB/SзїУжЮД
жПРдЊЫзЪДжЇРз†БиµДжЇРжґµзЫЦдЇЖе∞Пз®ЛеЇПеЇФзФ®з≠Йе§ЪдЄ™йҐЖеЯЯпЉМжѓПдЄ™йҐЖеЯЯйГљеМЕеРЂдЇЖдЄ∞еѓМзЪДеЃЮдЊЛеТМй°єзЫЃгАВињЩдЇЫжЇРз†БйГљжШѓеЯЇдЇОеРДиЗ™еє≥еП∞зЪДжЬАжЦ∞жКАжЬѓеТМж†ЗеЗЖзЉЦеЖЩпЉМз°ЃдњЭдЇЖеЬ®еѓєеЇФзОѓеҐГдЄЛиГље§ЯжЧ†зЉЭињРи°МгАВеРМжЧґпЉМжЇРз†БдЄ≠йЕНе§ЗдЇЖиѓ¶зїЖзЪДж≥®йЗКеТМжЦЗж°£пЉМеЄЃеК©зФ®жИЈењЂйАЯзРЖиІ£дї£з†БзїУжЮДеТМеЃЮзО∞йАїиЊСгАВ йАВзФ®дЇЇзЊ§пЉЪ йАВеРИжѓХдЄЪиЃЊиЃ°гАБиѓЊз®ЛиЃЊиЃ°дљЬдЄЪгАВињЩдЇЫжЇРз†БиµДжЇРзЙєеИЂйАВеРИе§Іе≠¶зФЯзЊ§дљУгАВжЧ†иЃЇдљ†жШѓиЃ°зЃЧжЬЇзЫЄеЕ≥дЄУдЄЪзЪДе≠¶зФЯпЉМињШжШѓеѓєеЕґдїЦйҐЖеЯЯзЉЦз®ЛжДЯеЕіиґ£зЪДе≠¶зФЯпЉМињЩдЇЫиµДжЇРйГљиГљдЄЇдљ†жПРдЊЫеЃЭиіµзЪДе≠¶дє†еТМеЃЮиЈµжЬЇдЉЪгАВйАЪињЗе≠¶дє†еТМињРи°МињЩдЇЫжЇРз†БпЉМдљ†еПѓдї•жОМжП°еРДеє≥еП∞еЉАеПСзЪДеЯЇз°АзЯ•иѓЖпЉМжПРеНЗзЉЦз®ЛиГљеКЫеТМй°єзЫЃеЃЮжИШзїПй™МгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪ еЬ®е≠¶дє†йШґжЃµпЉМдљ†еПѓдї•еИ©зФ®ињЩдЇЫжЇРз†БиµДжЇРињЫи°МиѓЊз®ЛеЃЮиЈµгАБиѓЊе§Цй°єзЫЃжИЦжѓХдЄЪиЃЊиЃ°гАВйАЪињЗеИЖжЮРеТМињРи°МжЇРз†БпЉМдљ†е∞ЖжЈ±еЕ•дЇЖиІ£еРДеє≥еП∞еЉАеПСзЪДжКАжЬѓзїЖиКВеТМжЬАдљ≥еЃЮиЈµпЉМйАРж≠•еЯєеЕїиµЈиЗ™еЈ±зЪДй°єзЫЃеЉАеПСеТМйЧЃйҐШиІ£еЖ≥иГљеКЫгАВж≠§е§ЦпЉМеЬ®ж±ВиБМжИЦеИЫдЄЪињЗз®ЛдЄ≠пЉМеЕЈе§ЗиЈ®еє≥еП∞еЉАеПСиГљеКЫзЪДе§Іе≠¶зФЯе∞ЖжЫіеЕЈзЂЮдЇЙеКЫгАВ еЕґдїЦиѓіжШОпЉЪ дЄЇдЇЖз°ЃдњЭжЇРз†БиµДжЇРзЪДеПѓињРи°МжАІеТМжШУзФ®жАІпЉМзЙєеИЂж≥®жДПдЇЖдї•дЄЛеЗ†зВєпЉЪй¶ЦеЕИпЉМжѓПдїљжЇРз†БйГљжПРдЊЫдЇЖиѓ¶зїЖзЪДињРи°МзОѓеҐГеТМдЊЭиµЦиѓіжШОпЉМз°ЃдњЭзФ®жИЈиГље§ЯиљїжЭЊжР≠еїЇиµЈеЉАеПСзОѓеҐГпЉЫеЕґжђ°пЉМжЇРз†БдЄ≠зЪДж≥®йЗКеТМжЦЗж°£йГљйЭЮеЄЄеЃМеЦДпЉМжЦєдЊњзФ®жИЈењЂйАЯдЄКжЙЛеТМзРЖиІ£дї£з†БпЉЫжЬАеРОпЉМжИСдЉЪеЃЪжЬЯжЫіжЦ∞ињЩдЇЫжЇРз†БиµДжЇРпЉМдї•йАВеЇФеРДеє≥еП∞жКАжЬѓзЪДжЬАжЦ∞еПСе±ХеТМеЄВеЬЇйЬАж±ВгАВ жЙАжЬЙжЇРз†БеЭЗзїПињЗдЄ•ж†ЉжµЛиѓХпЉМеПѓдї•зЫіжО•ињРи°МпЉМеПѓдї•жФЊењГдЄЛиљљдљњзФ®гАВжЬЙдїїдљХдљњзФ®йЧЃйҐШ搥ињОйЪПжЧґдЄОеНЪдЄїж≤ЯйАЪпЉМзђђдЄАжЧґйЧіињЫи°МиІ£з≠ФпЉБ
гАРеЊЃдњ°е∞Пз®ЛеЇПжѓХдЄЪиЃЊиЃ°гАСйЂШж†°ж†°еЫ≠дЇ§еПЛз≥їзїЯеЉАеПСй°єзЫЃ(жЇРз†Б+жЉФз§ЇиІЖйҐС+иѓіжШО).rar гАРй°єзЫЃжКАжЬѓгАС еЊЃдњ°е∞Пз®ЛеЇПеЉАеПСеЈ•еЕЈ+javaеРОзЂѓ+mysql гАРжЉФз§ЇиІЖйҐС-зЉЦеПЈпЉЪ262гАС https://pan.quark.cn/s/cb634e7c02b5 гАРеЃЮзО∞еКЯиГљгАС дЄ™дЇЇдЄ≠ењГзЃ°зРЖпЉМзФ®жИЈдњ°жБѓзЃ°зРЖпЉМеЕіиґ£зИ±е•љзЃ°зРЖпЉМеЕђеСКз±їеЮЛзЃ°зРЖпЉМиљЃжТ≠еЫЊзЃ°зРЖпЉМеЕђеСКдњ°жБѓзЃ°зРЖз≠Й
еЉєеєХиІЖйҐСзљСзЂЩжШѓдї•еЃЮйЩЕињРзФ®дЄЇеЉАеПСиГМжЩѓпЉМињРзФ®иљѓдїґеЈ•з®ЛеЉАеПСжЦєж≥ХпЉМйЗЗзФ®jspжКАжЬѓжЮДеїЇзЪДдЄАдЄ™зЃ°зРЖз≥їзїЯгАВжХідЄ™еЉАеПСињЗз®Лй¶ЦеЕИеѓєиљѓдїґз≥їзїЯињЫи°МйЬАж±ВеИЖжЮРпЉМеЊЧеЗЇз≥їзїЯзЪДдЄїи¶БеКЯиГљгАВжО•зЭАеѓєз≥їзїЯињЫи°МжАїдљУиЃЊиЃ°еТМиѓ¶зїЖиЃЊиЃ°гАВжАїдљУиЃЊиЃ°дЄїи¶БеМЕжЛђз≥їзїЯжАїдљУзїУжЮДиЃЊиЃ°гАБз≥їзїЯжХ∞жНЃзїУжЮДиЃЊиЃ°гАБз≥їзїЯеКЯиГљиЃЊиЃ°еТМз≥їзїЯеЃЙеЕ®иЃЊиЃ°з≠ЙпЉЫиѓ¶зїЖиЃЊиЃ°дЄїи¶БеМЕжЛђж®°еЭЧеЃЮзО∞зЪДеЕ≥йФЃдї£з†БпЉМз≥їзїЯжХ∞жНЃеЇУиЃњйЧЃеТМдЄїи¶БеКЯиГљж®°еЭЧзЪДеЕЈдљУеЃЮзО∞з≠ЙгАВжЬАеРОеѓєз≥їзїЯињЫи°МеКЯиГљжµЛиѓХпЉМеєґеѓєжµЛиѓХзїУжЮЬињЫи°МеИЖжЮРжАїзїУпЉМеПКжЧґжФєињЫз≥їзїЯдЄ≠е≠ШеЬ®зЪДдЄНиґ≥пЉМдЄЇдї•еРОзЪДз≥їзїЯзїіжК§жПРдЊЫдЇЖжЦєдЊњпЉМдєЯдЄЇдїКеРОеЉАеПСз±їдЉЉз≥їзїЯжПРдЊЫдЇЖеАЯйЙіеТМеЄЃеК©гАВ жЬђеЉєеєХиІЖйҐСзљСзЂЩйЗЗзФ®зЪДжХ∞жНЃеЇУжШѓMysqlпЉМдљњзФ®JSPжКАжЬѓеЉАеПСгАВеЬ®иЃЊиЃ°ињЗз®ЛдЄ≠пЉМеЕЕеИЖдњЭиѓБдЇЖз≥їзїЯдї£з†БзЪДиЙѓе•љеПѓиѓїжАІгАБеЃЮзФ®жАІгАБжШУжЙ©е±ХжАІгАБйАЪзФ®жАІгАБдЊњдЇОеРОжЬЯзїіжК§гАБжУНдљЬжЦєдЊњдї•еПКй°µйЭҐзЃАжіБз≠ЙзЙєзВєгАВ еЕ≥йФЃиѓНпЉЪеЉєеєХиІЖйҐСзљСзЂЩпЉМJSPжКАжЬѓпЉМMysqlжХ∞жНЃеЇУ
жПРдЊЫзЪДжЇРз†БиµДжЇРжґµзЫЦдЇЖJavaеЇФзФ®з≠Йе§ЪдЄ™йҐЖеЯЯпЉМжѓПдЄ™йҐЖеЯЯйГљеМЕеРЂдЇЖдЄ∞еѓМзЪДеЃЮдЊЛеТМй°єзЫЃгАВињЩдЇЫжЇРз†БйГљжШѓеЯЇдЇОеРДиЗ™еє≥еП∞зЪДжЬАжЦ∞жКАжЬѓеТМж†ЗеЗЖзЉЦеЖЩпЉМз°ЃдњЭдЇЖеЬ®еѓєеЇФзОѓеҐГдЄЛиГље§ЯжЧ†зЉЭињРи°МгАВеРМжЧґпЉМжЇРз†БдЄ≠йЕНе§ЗдЇЖиѓ¶зїЖзЪДж≥®йЗКеТМжЦЗж°£пЉМеЄЃеК©зФ®жИЈењЂйАЯзРЖиІ£дї£з†БзїУжЮДеТМеЃЮзО∞йАїиЊСгАВ йАВзФ®дЇЇзЊ§пЉЪ йАВеРИжѓХдЄЪиЃЊиЃ°гАБиѓЊз®ЛиЃЊиЃ°дљЬдЄЪгАВињЩдЇЫжЇРз†БиµДжЇРзЙєеИЂйАВеРИе§Іе≠¶зФЯзЊ§дљУгАВжЧ†иЃЇдљ†жШѓиЃ°зЃЧжЬЇзЫЄеЕ≥дЄУдЄЪзЪДе≠¶зФЯпЉМињШжШѓеѓєеЕґдїЦйҐЖеЯЯзЉЦз®ЛжДЯеЕіиґ£зЪДе≠¶зФЯпЉМињЩдЇЫиµДжЇРйГљиГљдЄЇдљ†жПРдЊЫеЃЭиіµзЪДе≠¶дє†еТМеЃЮиЈµжЬЇдЉЪгАВйАЪињЗе≠¶дє†еТМињРи°МињЩдЇЫжЇРз†БпЉМдљ†еПѓдї•жОМжП°еРДеє≥еП∞еЉАеПСзЪДеЯЇз°АзЯ•иѓЖпЉМжПРеНЗзЉЦз®ЛиГљеКЫеТМй°єзЫЃеЃЮжИШзїПй™МгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪ еЬ®е≠¶дє†йШґжЃµпЉМдљ†еПѓдї•еИ©зФ®ињЩдЇЫжЇРз†БиµДжЇРињЫи°МиѓЊз®ЛеЃЮиЈµгАБиѓЊе§Цй°єзЫЃжИЦжѓХдЄЪиЃЊиЃ°гАВйАЪињЗеИЖжЮРеТМињРи°МжЇРз†БпЉМдљ†е∞ЖжЈ±еЕ•дЇЖиІ£еРДеє≥еП∞еЉАеПСзЪДжКАжЬѓзїЖиКВеТМжЬАдљ≥еЃЮиЈµпЉМйАРж≠•еЯєеЕїиµЈиЗ™еЈ±зЪДй°єзЫЃеЉАеПСеТМйЧЃйҐШиІ£еЖ≥иГљеКЫгАВж≠§е§ЦпЉМеЬ®ж±ВиБМжИЦеИЫдЄЪињЗз®ЛдЄ≠пЉМеЕЈе§ЗиЈ®еє≥еП∞еЉАеПСиГљеКЫзЪДе§Іе≠¶зФЯе∞ЖжЫіеЕЈзЂЮдЇЙеКЫгАВ еЕґдїЦиѓіжШОпЉЪ дЄЇдЇЖз°ЃдњЭжЇРз†БиµДжЇРзЪДеПѓињРи°МжАІеТМжШУзФ®жАІпЉМзЙєеИЂж≥®жДПдЇЖдї•дЄЛеЗ†зВєпЉЪй¶ЦеЕИпЉМжѓПдїљжЇРз†БйГљжПРдЊЫдЇЖиѓ¶зїЖзЪДињРи°МзОѓеҐГеТМдЊЭиµЦиѓіжШОпЉМз°ЃдњЭзФ®жИЈиГље§ЯиљїжЭЊжР≠еїЇиµЈеЉАеПСзОѓеҐГпЉЫеЕґжђ°пЉМжЇРз†БдЄ≠зЪДж≥®йЗКеТМжЦЗж°£йГљйЭЮеЄЄеЃМеЦДпЉМжЦєдЊњзФ®жИЈењЂйАЯдЄКжЙЛеТМзРЖиІ£дї£з†БпЉЫжЬАеРОпЉМжИСдЉЪеЃЪжЬЯжЫіжЦ∞ињЩдЇЫжЇРз†БиµДжЇРпЉМдї•йАВеЇФеРДеє≥еП∞жКАжЬѓзЪДжЬАжЦ∞еПСе±ХеТМеЄВеЬЇйЬАж±ВгАВ жЙАжЬЙжЇРз†БеЭЗзїПињЗдЄ•ж†ЉжµЛиѓХпЉМеПѓдї•зЫіжО•ињРи°МпЉМеПѓдї•жФЊењГдЄЛиљљдљњзФ®гАВжЬЙдїїдљХдљњзФ®йЧЃйҐШ搥ињОйЪПжЧґдЄОеНЪдЄїж≤ЯйАЪпЉМзђђдЄАжЧґйЧіињЫи°МиІ£з≠ФпЉБ
жПРдЊЫзЪДжЇРз†БиµДжЇРжґµзЫЦдЇЖе∞Пз®ЛеЇПеЇФзФ®з≠Йе§ЪдЄ™йҐЖеЯЯпЉМжѓПдЄ™йҐЖеЯЯйГљеМЕеРЂдЇЖдЄ∞еѓМзЪДеЃЮдЊЛеТМй°єзЫЃгАВињЩдЇЫжЇРз†БйГљжШѓеЯЇдЇОеРДиЗ™еє≥еП∞зЪДжЬАжЦ∞жКАжЬѓеТМж†ЗеЗЖзЉЦеЖЩпЉМз°ЃдњЭдЇЖеЬ®еѓєеЇФзОѓеҐГдЄЛиГље§ЯжЧ†зЉЭињРи°МгАВеРМжЧґпЉМжЇРз†БдЄ≠йЕНе§ЗдЇЖиѓ¶зїЖзЪДж≥®йЗКеТМжЦЗж°£пЉМеЄЃеК©зФ®жИЈењЂйАЯзРЖиІ£дї£з†БзїУжЮДеТМеЃЮзО∞йАїиЊСгАВ йАВзФ®дЇЇзЊ§пЉЪ йАВеРИжѓХдЄЪиЃЊиЃ°гАБиѓЊз®ЛиЃЊиЃ°дљЬдЄЪгАВињЩдЇЫжЇРз†БиµДжЇРзЙєеИЂйАВеРИе§Іе≠¶зФЯзЊ§дљУгАВжЧ†иЃЇдљ†жШѓиЃ°зЃЧжЬЇзЫЄеЕ≥дЄУдЄЪзЪДе≠¶зФЯпЉМињШжШѓеѓєеЕґдїЦйҐЖеЯЯзЉЦз®ЛжДЯеЕіиґ£зЪДе≠¶зФЯпЉМињЩдЇЫиµДжЇРйГљиГљдЄЇдљ†жПРдЊЫеЃЭиіµзЪДе≠¶дє†еТМеЃЮиЈµжЬЇдЉЪгАВйАЪињЗе≠¶дє†еТМињРи°МињЩдЇЫжЇРз†БпЉМдљ†еПѓдї•жОМжП°еРДеє≥еП∞еЉАеПСзЪДеЯЇз°АзЯ•иѓЖпЉМжПРеНЗзЉЦз®ЛиГљеКЫеТМй°єзЫЃеЃЮжИШзїПй™МгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪ еЬ®е≠¶дє†йШґжЃµпЉМдљ†еПѓдї•еИ©зФ®ињЩдЇЫжЇРз†БиµДжЇРињЫи°МиѓЊз®ЛеЃЮиЈµгАБиѓЊе§Цй°єзЫЃжИЦжѓХдЄЪиЃЊиЃ°гАВйАЪињЗеИЖжЮРеТМињРи°МжЇРз†БпЉМдљ†е∞ЖжЈ±еЕ•дЇЖиІ£еРДеє≥еП∞еЉАеПСзЪДжКАжЬѓзїЖиКВеТМжЬАдљ≥еЃЮиЈµпЉМйАРж≠•еЯєеЕїиµЈиЗ™еЈ±зЪДй°єзЫЃеЉАеПСеТМйЧЃйҐШиІ£еЖ≥иГљеКЫгАВж≠§е§ЦпЉМеЬ®ж±ВиБМжИЦеИЫдЄЪињЗз®ЛдЄ≠пЉМеЕЈе§ЗиЈ®еє≥еП∞еЉАеПСиГљеКЫзЪДе§Іе≠¶зФЯе∞ЖжЫіеЕЈзЂЮдЇЙеКЫгАВ еЕґдїЦиѓіжШОпЉЪ дЄЇдЇЖз°ЃдњЭжЇРз†БиµДжЇРзЪДеПѓињРи°МжАІеТМжШУзФ®жАІпЉМзЙєеИЂж≥®жДПдЇЖдї•дЄЛеЗ†зВєпЉЪй¶ЦеЕИпЉМжѓПдїљжЇРз†БйГљжПРдЊЫдЇЖиѓ¶зїЖзЪДињРи°МзОѓеҐГеТМдЊЭиµЦиѓіжШОпЉМз°ЃдњЭзФ®жИЈиГље§ЯиљїжЭЊжР≠еїЇиµЈеЉАеПСзОѓеҐГпЉЫеЕґжђ°пЉМжЇРз†БдЄ≠зЪДж≥®йЗКеТМжЦЗж°£йГљйЭЮеЄЄеЃМеЦДпЉМжЦєдЊњзФ®жИЈењЂйАЯдЄКжЙЛеТМзРЖиІ£дї£з†БпЉЫжЬАеРОпЉМжИСдЉЪеЃЪжЬЯжЫіжЦ∞ињЩдЇЫжЇРз†БиµДжЇРпЉМдї•йАВеЇФеРДеє≥еП∞жКАжЬѓзЪДжЬАжЦ∞еПСе±ХеТМеЄВеЬЇйЬАж±ВгАВ жЙАжЬЙжЇРз†БеЭЗзїПињЗдЄ•ж†ЉжµЛиѓХпЉМеПѓдї•зЫіжО•ињРи°МпЉМеПѓдї•жФЊењГдЄЛиљљдљњзФ®гАВжЬЙдїїдљХдљњзФ®йЧЃйҐШ搥ињОйЪПжЧґдЄОеНЪдЄїж≤ЯйАЪпЉМзђђдЄАжЧґйЧіињЫи°МиІ£з≠ФпЉБ
е§Іж®°еЮЛжЧґдї£ жЬАе§ІеМЦCPUдїЈеАЉзЪДдЉШеМЦз≠ЦзХ•-дљХжЩЃж±Я
Node.jsпЉМзЃАзІ∞NodeпЉМжШѓдЄАдЄ™еЉАжЇРдЄФиЈ®еє≥еП∞зЪДJavaScriptињРи°МжЧґзОѓеҐГпЉМеЃГеЕБиЃЄеЬ®жµПиІИеЩ®е§ЦињРи°МJavaScriptдї£з†БгАВNode.jsдЇО2009еєізФ±Ryan DahlеИЫзЂЛпЉМжЧ®еЬ®еИЫеїЇйЂШжАІиГљзЪДWebжЬНеК°еЩ®еТМзљСзїЬеЇФзФ®з®ЛеЇПгАВеЃГеЯЇдЇОGoogle ChromeзЪДV8 JavaScriptеЉХжУОпЉМеПѓдї•еЬ®WindowsгАБLinuxгАБUnixгАБMac OS Xз≠ЙжУНдљЬз≥їзїЯдЄКињРи°МгАВ Node.jsзЪДзЙєзВєдєЛдЄАжШѓдЇЛдїґй©±еК®еТМйЭЮйШїе°ЮI/Oж®°еЮЛпЉМињЩдљњеЊЧеЃГйЭЮеЄЄйАВеРИе§ДзРЖе§ІйЗПеєґеПСињЮжО•пЉМдїОиАМеЬ®жЮДеїЇеЃЮжЧґеЇФзФ®з®ЛеЇПе¶ВеЬ®зЇњжЄЄжИПгАБиБК姩еЇФзФ®дї•еПКеЃЮжЧґйАЪиЃѓжЬНеК°жЧґи°®зО∞еНУиґКгАВж≠§е§ЦпЉМNode.jsдљњзФ®дЇЖж®°еЭЧеМЦзЪДжЮґжЮДпЉМйАЪињЗnpmпЉИNode package managerпЉМNodeеМЕзЃ°зРЖеЩ®пЉЙ,з§ЊеМЇжИРеСШеПѓдї•еЕ±дЇЂеТМе§НзФ®дї£з†БпЉМжЮБе§ІеЬ∞дњГињЫдЇЖNode.jsзФЯжАБз≥їзїЯзЪДеПСе±ХеТМжЙ©еЉ†гАВ Node.jsдЄНдїЕзФ®дЇОжЬНеК°еЩ®зЂѓеЉАеПСгАВйЪПзЭАжКАжЬѓзЪДеПСе±ХпЉМеЃГдєЯ襀зФ®дЇОжЮДеїЇеЈ•еЕЈйУЊгАБеЉАеПСж°МйЭҐеЇФзФ®з®ЛеЇПгАБзЙ©иБФзљСиЃЊе§Зз≠ЙгАВNode.jsиГље§Яе§ДзРЖжЦЗдїґз≥їзїЯгАБжУНдљЬжХ∞жНЃеЇУгАБе§ДзРЖзљСзїЬиѓЈж±Вз≠ЙпЉМеЫ†ж≠§пЉМеЉАеПСиАЕеПѓдї•зФ®JavaScriptзЉЦеЖЩеЕ®ж†ИеЇФзФ®з®ЛеЇПпЉМињЩдЄАзВєе§Іе§ІжПРйЂШдЇЖеЉАеПСжХИзОЗеТМдЊњжНЈжАІгАВ еЬ®еЃЮиЈµдЄ≠пЉМиЃЄе§Ъе§ІеЮЛдЉБдЄЪеТМзїДзїЗеЈ≤зїПйЗЗзФ®Node.jsдљЬдЄЇеЕґWebеЇФзФ®з®ЛеЇПзЪДеЉАеПСеє≥еП∞пЉМе¶ВNetflixгАБPayPalеТМWalmartз≠ЙгАВеЃГдїђеИ©зФ®Node.jsжПРйЂШдЇЖеЇФзФ®жАІиГљпЉМзЃАеМЦдЇЖеЉАеПСжµБз®ЛпЉМеєґдЄФиГљжЫіењЂеЬ∞еУНеЇФеЄВеЬЇйЬАж±ВгАВ
е§ІжХ∞жНЃжКАжЬѓжМЗзЪДжШѓзФ®дЇОе§ДзРЖеТМеИЖжЮРе§ІиІДж®°жХ∞жНЃйЫЖзЪДжКАжЬѓеТМеЈ•еЕЈгАВдї•дЄЛжШѓдЄАдЇЫеЄЄиІБзЪДе§ІжХ∞жНЃжКАжЬѓеТМеЈ•еЕЈпЉЪ HadoopпЉЪApache HadoopжШѓдЄАдЄ™зФ®дЇОеИЖеЄГеЉПе≠ШеВ®еТМе§ДзРЖе§ІиІДж®°жХ∞жНЃзЪДеЉАжЇРж°ЖжЮґгАВеЃГеМЕжЛђHadoop Distributed File SystemпЉИHDFSпЉЙзФ®дЇОжХ∞жНЃе≠ШеВ®еТМMapReduceзФ®дЇОжХ∞жНЃе§ДзРЖгАВ SparkпЉЪApache SparkжШѓдЄАдЄ™ењЂйАЯгАБйАЪзФ®зЪДйЫЖзЊ§иЃ°зЃЧз≥їзїЯпЉМжПРдЊЫдЇЖжѓФMapReduceжЫіењЂзЪДжХ∞жНЃе§ДзРЖиГљеКЫгАВеЃГжФѓжМБеЖЕе≠ШиЃ°зЃЧеТМжЫіе§Ъе§НжЭВзЪДжХ∞жНЃе§ДзРЖжµБз®ЛгАВ NoSQLжХ∞жНЃеЇУпЉЪNoSQLжХ∞жНЃеЇУпЉИе¶ВMongoDBгАБCassandraз≠ЙпЉЙеИЩжЫійАВзФ®дЇОе§ДзРЖињЩз±їжХ∞жНЃгАВ жХ∞жНЃдїУеЇУпЉЪжХ∞жНЃдїУеЇУжШѓдЄАдЄ™зФ®дЇОйЫЖжИРеТМеИЖжЮРе§ІиІДж®°жХ∞жНЃзЪДе≠ШеВ®з≥їзїЯпЉМдЄАдЇЫзЯ•еРНзЪДжХ∞жНЃдїУеЇУеМЕжЛђSnowflakeгАБAmazon Redshiftз≠ЙгАВ жХ∞жНЃжєЦпЉЪжХ∞жНЃжєЦжШѓдЄАдЄ™е≠ШеВ®зїУжЮДеМЦеТМйЭЮзїУжЮДеМЦжХ∞жНЃзЪДе≠Ше®汆пЉМзФ®дЇОжФѓжМБжХ∞жНЃеИЖжЮРеТМжЬЇеЩ®е≠¶дє†еЇФзФ®гАВ жЬЇеЩ®е≠¶дє†пЉЪе§ІжХ∞жНЃжКАжЬѓдєЯеєњж≥ЫеЇФзФ®дЇОжЬЇеЩ®е≠¶дє†йҐЖеЯЯпЉМжФѓжМБе§ІиІДж®°жХ∞жНЃзЪДж®°еЮЛиЃ≠зїГеТМйҐДжµЛеИЖжЮРгАВ жµБеЉПе§ДзРЖпЉЪйТИеѓєеЃЮжЧґжХ∞жНЃе§ДзРЖйЬАж±ВпЉМжµБеЉПе§ДзРЖжКАжЬѓпЉИе¶ВApache KafkaгАБApache FlinkпЉЙеПѓдї•еЃЮжЧґгАВ
Node.jsпЉМзЃАзІ∞NodeпЉМжШѓдЄАдЄ™еЉАжЇРдЄФиЈ®еє≥еП∞зЪДJavaScriptињРи°МжЧґзОѓеҐГпЉМеЃГеЕБиЃЄеЬ®жµПиІИеЩ®е§ЦињРи°МJavaScriptдї£з†БгАВNode.jsдЇО2009еєізФ±Ryan DahlеИЫзЂЛпЉМжЧ®еЬ®еИЫеїЇйЂШжАІиГљзЪДWebжЬНеК°еЩ®еТМзљСзїЬеЇФзФ®з®ЛеЇПгАВеЃГеЯЇдЇОGoogle ChromeзЪДV8 JavaScriptеЉХжУОпЉМеПѓдї•еЬ®WindowsгАБLinuxгАБUnixгАБMac OS Xз≠ЙжУНдљЬз≥їзїЯдЄКињРи°МгАВ Node.jsзЪДзЙєзВєдєЛдЄАжШѓдЇЛдїґй©±еК®еТМйЭЮйШїе°ЮI/Oж®°еЮЛпЉМињЩдљњеЊЧеЃГйЭЮеЄЄйАВеРИе§ДзРЖе§ІйЗПеєґеПСињЮжО•пЉМдїОиАМеЬ®жЮДеїЇеЃЮжЧґеЇФзФ®з®ЛеЇПе¶ВеЬ®зЇњжЄЄжИПгАБиБК姩еЇФзФ®дї•еПКеЃЮжЧґйАЪиЃѓжЬНеК°жЧґи°®зО∞еНУиґКгАВж≠§е§ЦпЉМNode.jsдљњзФ®дЇЖж®°еЭЧеМЦзЪДжЮґжЮДпЉМйАЪињЗnpmпЉИNode package managerпЉМNodeеМЕзЃ°зРЖеЩ®пЉЙ,з§ЊеМЇжИРеСШеПѓдї•еЕ±дЇЂеТМе§НзФ®дї£з†БпЉМжЮБе§ІеЬ∞дњГињЫдЇЖNode.jsзФЯжАБз≥їзїЯзЪДеПСе±ХеТМжЙ©еЉ†гАВ Node.jsдЄНдїЕзФ®дЇОжЬНеК°еЩ®зЂѓеЉАеПСгАВйЪПзЭАжКАжЬѓзЪДеПСе±ХпЉМеЃГдєЯ襀зФ®дЇОжЮДеїЇеЈ•еЕЈйУЊгАБеЉАеПСж°МйЭҐеЇФзФ®з®ЛеЇПгАБзЙ©иБФзљСиЃЊе§Зз≠ЙгАВNode.jsиГље§Яе§ДзРЖжЦЗдїґз≥їзїЯгАБжУНдљЬжХ∞жНЃеЇУгАБе§ДзРЖзљСзїЬиѓЈж±Вз≠ЙпЉМеЫ†ж≠§пЉМеЉАеПСиАЕеПѓдї•зФ®JavaScriptзЉЦеЖЩеЕ®ж†ИеЇФзФ®з®ЛеЇПпЉМињЩдЄАзВєе§Іе§ІжПРйЂШдЇЖеЉАеПСжХИзОЗеТМдЊњжНЈжАІгАВ еЬ®еЃЮиЈµдЄ≠пЉМиЃЄе§Ъе§ІеЮЛдЉБдЄЪеТМзїДзїЗеЈ≤зїПйЗЗзФ®Node.jsдљЬдЄЇеЕґWebеЇФзФ®з®ЛеЇПзЪДеЉАеПСеє≥еП∞пЉМе¶ВNetflixгАБPayPalеТМWalmartз≠ЙгАВеЃГдїђеИ©зФ®Node.jsжПРйЂШдЇЖеЇФзФ®жАІиГљпЉМзЃАеМЦдЇЖеЉАеПСжµБз®ЛпЉМеєґдЄФиГљжЫіењЂеЬ∞еУНеЇФеЄВеЬЇйЬАж±ВгАВ
е§ІжХ∞жНЃжКАжЬѓжМЗзЪДжШѓзФ®дЇОе§ДзРЖеТМеИЖжЮРе§ІиІДж®°жХ∞жНЃйЫЖзЪДжКАжЬѓеТМеЈ•еЕЈгАВдї•дЄЛжШѓдЄАдЇЫеЄЄиІБзЪДе§ІжХ∞жНЃжКАжЬѓеТМеЈ•еЕЈпЉЪ HadoopпЉЪApache HadoopжШѓдЄАдЄ™зФ®дЇОеИЖеЄГеЉПе≠ШеВ®еТМе§ДзРЖе§ІиІДж®°жХ∞жНЃзЪДеЉАжЇРж°ЖжЮґгАВеЃГеМЕжЛђHadoop Distributed File SystemпЉИHDFSпЉЙзФ®дЇОжХ∞жНЃе≠ШеВ®еТМMapReduceзФ®дЇОжХ∞жНЃе§ДзРЖгАВ SparkпЉЪApache SparkжШѓдЄАдЄ™ењЂйАЯгАБйАЪзФ®зЪДйЫЖзЊ§иЃ°зЃЧз≥їзїЯпЉМжПРдЊЫдЇЖжѓФMapReduceжЫіењЂзЪДжХ∞жНЃе§ДзРЖиГљеКЫгАВеЃГжФѓжМБеЖЕе≠ШиЃ°зЃЧеТМжЫіе§Ъе§НжЭВзЪДжХ∞жНЃе§ДзРЖжµБз®ЛгАВ NoSQLжХ∞жНЃеЇУпЉЪNoSQLжХ∞жНЃеЇУпЉИе¶ВMongoDBгАБCassandraз≠ЙпЉЙеИЩжЫійАВзФ®дЇОе§ДзРЖињЩз±їжХ∞жНЃгАВ жХ∞жНЃдїУеЇУпЉЪжХ∞жНЃдїУеЇУжШѓдЄАдЄ™зФ®дЇОйЫЖжИРеТМеИЖжЮРе§ІиІДж®°жХ∞жНЃзЪДе≠ШеВ®з≥їзїЯпЉМдЄАдЇЫзЯ•еРНзЪДжХ∞жНЃдїУеЇУеМЕжЛђSnowflakeгАБAmazon Redshiftз≠ЙгАВ жХ∞жНЃжєЦпЉЪжХ∞жНЃжєЦжШѓдЄАдЄ™е≠ШеВ®зїУжЮДеМЦеТМйЭЮзїУжЮДеМЦжХ∞жНЃзЪДе≠Ше®汆пЉМзФ®дЇОжФѓжМБжХ∞жНЃеИЖжЮРеТМжЬЇеЩ®е≠¶дє†еЇФзФ®гАВ жЬЇеЩ®е≠¶дє†пЉЪе§ІжХ∞жНЃжКАжЬѓдєЯеєњж≥ЫеЇФзФ®дЇОжЬЇеЩ®е≠¶дє†йҐЖеЯЯпЉМжФѓжМБе§ІиІДж®°жХ∞жНЃзЪДж®°еЮЛиЃ≠зїГеТМйҐДжµЛеИЖжЮРгАВ жµБеЉПе§ДзРЖпЉЪйТИеѓєеЃЮжЧґжХ∞жНЃе§ДзРЖйЬАж±ВпЉМжµБеЉПе§ДзРЖжКАжЬѓпЉИе¶ВApache KafkaгАБApache FlinkпЉЙеПѓдї•еЃЮжЧґгАВ
е§ІжХ∞жНЃжКАжЬѓжМЗзЪДжШѓзФ®дЇОе§ДзРЖеТМеИЖжЮРе§ІиІДж®°жХ∞жНЃйЫЖзЪДжКАжЬѓеТМеЈ•еЕЈгАВдї•дЄЛжШѓдЄАдЇЫеЄЄиІБзЪДе§ІжХ∞жНЃжКАжЬѓеТМеЈ•еЕЈпЉЪ HadoopпЉЪApache HadoopжШѓдЄАдЄ™зФ®дЇОеИЖеЄГеЉПе≠ШеВ®еТМе§ДзРЖе§ІиІДж®°жХ∞жНЃзЪДеЉАжЇРж°ЖжЮґгАВеЃГеМЕжЛђHadoop Distributed File SystemпЉИHDFSпЉЙзФ®дЇОжХ∞жНЃе≠ШеВ®еТМMapReduceзФ®дЇОжХ∞жНЃе§ДзРЖгАВ SparkпЉЪApache SparkжШѓдЄАдЄ™ењЂйАЯгАБйАЪзФ®зЪДйЫЖзЊ§иЃ°зЃЧз≥їзїЯпЉМжПРдЊЫдЇЖжѓФMapReduceжЫіењЂзЪДжХ∞жНЃе§ДзРЖиГљеКЫгАВеЃГжФѓжМБеЖЕе≠ШиЃ°зЃЧеТМжЫіе§Ъе§НжЭВзЪДжХ∞жНЃе§ДзРЖжµБз®ЛгАВ NoSQLжХ∞жНЃеЇУпЉЪNoSQLжХ∞жНЃеЇУпЉИе¶ВMongoDBгАБCassandraз≠ЙпЉЙеИЩжЫійАВзФ®дЇОе§ДзРЖињЩз±їжХ∞жНЃгАВ жХ∞жНЃдїУеЇУпЉЪжХ∞жНЃдїУеЇУжШѓдЄАдЄ™зФ®дЇОйЫЖжИРеТМеИЖжЮРе§ІиІДж®°жХ∞жНЃзЪДе≠ШеВ®з≥їзїЯпЉМдЄАдЇЫзЯ•еРНзЪДжХ∞жНЃдїУеЇУеМЕжЛђSnowflakeгАБAmazon Redshiftз≠ЙгАВ жХ∞жНЃжєЦпЉЪжХ∞жНЃжєЦжШѓдЄАдЄ™е≠ШеВ®зїУжЮДеМЦеТМйЭЮзїУжЮДеМЦжХ∞жНЃзЪДе≠Ше®汆пЉМзФ®дЇОжФѓжМБжХ∞жНЃеИЖжЮРеТМжЬЇеЩ®е≠¶дє†еЇФзФ®гАВ жЬЇеЩ®е≠¶дє†пЉЪе§ІжХ∞жНЃжКАжЬѓдєЯеєњж≥ЫеЇФзФ®дЇОжЬЇеЩ®е≠¶дє†йҐЖеЯЯпЉМжФѓжМБе§ІиІДж®°жХ∞жНЃзЪДж®°еЮЛиЃ≠зїГеТМйҐДжµЛеИЖжЮРгАВ жµБеЉПе§ДзРЖпЉЪйТИеѓєеЃЮжЧґжХ∞жНЃе§ДзРЖйЬАж±ВпЉМжµБеЉПе§ДзРЖжКАжЬѓпЉИе¶ВApache KafkaгАБApache FlinkпЉЙеПѓдї•еЃЮжЧґгАВ